PCAP + Protocol Research
Analyzed packet captures from the 2023 UNB CIC Modbus dataset to understand which fields, byte patterns, and protocol structures mattered for AI-assisted threat analysis.
An internal Siemens research project with two main tracks: an LLM-based alert-enrichment workflow backed by asset and CVE context, and AI-assisted traffic analysis using PCAPs from the 2023 UNB CIC Modbus dataset.
Analyzed packet captures from the 2023 UNB CIC Modbus dataset to understand which fields, byte patterns, and protocol structures mattered for AI-assisted threat analysis.
Evaluated open-source models that were already fine-tuned for cybersecurity, prepared structured JSON training data for Azure fine-tuning, and compared those paths against one-shot, multi-shot, and chain-of-thought prompting for packet reasoning.
Designed a workflow where AI agents could generate expected traffic frames or behavioral baselines, compare them against observed traffic, and pass invalid outputs back through a correction step instead of relying on a single-pass classifier.
I worked on this project with a co-op student to investigate where AI could actually help security analysis rather than just generate convincing text. One track focused on alert enrichment, where we combined dummy asset records stored in PostgreSQL with current CVE information so an LLM could explain why a system might be vulnerable and relate that risk back to the asset under investigation.
The second track focused on packet analysis using PCAPs from the 2023 UNB CIC Modbus dataset. We evaluated open-source models already fine-tuned for cybersecurity, prepared structured JSON training data for Azure fine-tuning, and reformatted the dataset traffic into higher-level flow and prompt representations to test whether the models could distinguish benign from anomalous behavior more reliably.
Started with raw packet bytes from PCAPs and mapped out which byte sequences, packet fields, and protocol segments should be inspected, skipped, or preserved as context for the model.
Converted packet-analysis findings into structured JSON for Azure fine-tuning while also benchmarking open-source cybersecurity-tuned models against the same packet-analysis problem.
Shifted from direct hex reasoning toward NetFlow-style and protocol-aware summaries so the model could reason over communication patterns, metadata, and expected behavior rather than only raw bytes.
One track focused on alert enrichment. We set up a PostgreSQL database with dummy asset records so an LLM could query internal asset context, match it against current CVE information, and generate vulnerability explanations and supporting analysis for the alert being investigated.
The goal was to give the model more than just the alert text. By combining asset details, vulnerability records, and current CVE context, the workflow could explain why a system might be exposed, what the likely risk meant, and how the vulnerability related back to the asset under investigation.

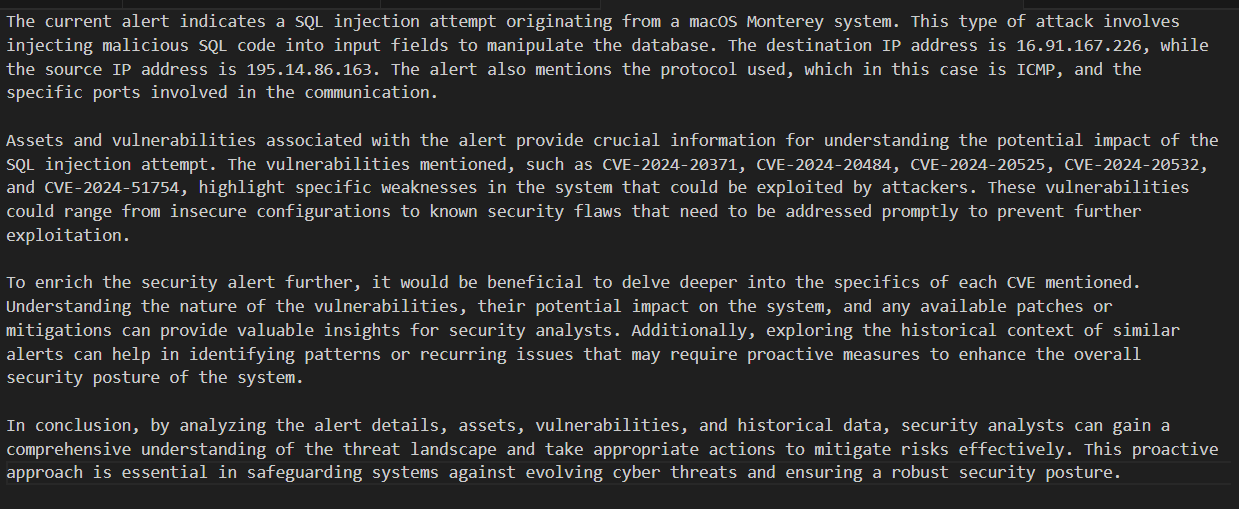
With PCAPs from the 2023 UNB CIC Modbus dataset represented as structured flows and prompts, we then compared different ways of classifying benign versus anomalous industrial traffic. The main question was which workflow still held up once the traffic started to vary from the examples we had prepared.
These results pushed the project away from treating the model as a standalone detector. Fine-tuning worked best when traffic stayed close to the training structure, prompt-based approaches were more flexible but still not accurate enough on their own, and the agentic validation idea looked more promising because it added control and feedback around the model output.
Fine-tuned models performed efficiently when the incoming PCAP closely matched the traffic structure seen in the training examples, but the approach degraded when the packet patterns varied from the baseline.
One-shot, multi-shot, and chain-of-thought prompting handled variation better than fine-tuning alone, but the outputs were still not accurate enough to be trusted as a reliable threat-detection workflow.
A more agentic pipeline showed better potential by having models generate expected frames or baselines, compare them with observed traffic, and use a feedback loop to reject and regenerate invalid analyses.
The main takeaway was that LLMs were not reliable enough for exact byte counting or raw hex interpretation on their own, but they became more useful when the input was transformed into structured protocol or flow context and placed inside a validated analysis loop.
The project was put on hold after the co-op term ended, but it clarified where AI fits best in security analysis: narrow fine-tuned workflows can work on consistent traffic structures, while prompt-based and agentic approaches are better for variation when paired with preprocessing, structure, and validation rather than treated as a standalone detection engine.